Project Overview
Our Client is building the world biggest all-in-one wine auctions data center, with aggregating data from over 20+ well-known auctions houses. All the data are publicly available on respective auction websites. The target data includes information about auctions and lots, for example, name, location, prices, volumes, estimated price, etc.
Given the client has a strong need of using these data for analytics and price comparisons, the platform must normalize all scraped wine data and map each item to the industry’s unique wine identifier—LWIN (Liv-ex Wine Identification Number). This requires large-scale fuzzy matching against a reference dataset of hundreds of thousands of standardized wine records.
In addition, the client requires a front-end admin website to view, manage, and verify the scraped and matched data, including lots, auctions, and sales results. The dashboard also supports advanced filtering, searching, and both auction-level and lot-level inspection.

Challanges
The red wine auction ecosystem is highly fragmented. Naming conventions and data formats vary significantly across countries, regions, wineries, and auction houses. There is no universal standard for key attributes such as wine names, vintage labeling, packaging, or volume declarations.
For example, a volume like “6 x 75cl” might appear as:
- “6 bottles”
- “6x750”
- “6 x 0.75L”
- “6 bts”
There are roughly 20–30 commonly used packaging formats, and each has dozens of textual variations. These inconsistencies make data extraction and normalization extremely challenging.
Moreover, inconsistency in naming of lots and wines makes a big difficulty in matching. For example, a lot titled “6 Bottles of Lafite 82 Pauillac - OWC” must be mapped to “Château Lafite Rothschild, Pauillac, 1982”. The lot name omits key identifiers like “Château” and “Rothschild”, abbreviates the vintage as “82”, and includes packaging details that interfere with exact matching. Without intelligent preprocessing and fuzzy matching, such entries would fail to align with the correct standardized record.
Additionally, edge cases in the data present structural challenges. Some lots may contain multiple wines—from different producers, with different vintages, or packaged in different formats. Without a well-designed, normalized database schema, querying or aggregating these complex lots would become difficult in downstream analysis or UI rendering.
Solutions
1. Modular Scraping
In order to handle the complexity and diversity of over 20 wine auction websites, the system is built on a modular scraping framework combining Scrapy with Playwright. This hybrid setup ensures repeat logic like proxy, user-agent, and database pipelines, etc, are re-used across all scrapers, instead of wasting time configure for all of them. It also allows site-specific logic to be easily maintained through configuration. New auction houses can be added with minimal overhead, enabling scalable expansion without compromising system stability.
2. Data Processing
Once the raw data is collected for every auction house, a custom-built parsing engine interprets and structures the unstructured raw data. This engine uses a combination of regular expressions, normalization rules, and domain-specific heuristics to extract key information such as wine name, vintage, volume, and unit format. It is designed to handle a wide range of packaging notations, including over 20 commonly seen unit formats—such as “6x75cl”, “6 bottles”, or “6 x 0.75L”—mapping them into a unified format that can be consistently stored and queried. If any error exists during the scraping because of a unconsidered new rule, proper loggings and exceptions will be throwed and recorded for future fix.
3. Data Normalization
To support accurate cross-region price comparisons, the system normalizes all monetary values into a common currency. This involves detecting the currency used in each listing and applying the exchange rates at the time of auction starts, which allows downstream users to perform meaningful analyses without worrying about currency inconsistencies.
4. Database
The underlying PostgreSQL schema has been carefully designed to reflect the complexity of wine lots. Each auction contains multiple lot and one record of auction sales data, each lot is represented as a normalized record that can contain one or multiple sub-items (lot items), supporting cases where a single lot includes wines from different producers, vintages, or formats. This schema not only ensures data consistency and flexibility but also provides a reliable foundation for advanced querying and analytical tasks in later stages.
5. LWIN Matching
A key component of the platform is the LWIN matching engine, which maps each lot to a standardized wine identifier. The engine uses BM25s algorithm, returning the top-k of most relevant matches with an associated confidence score. After that, the system validate the record by checking if fuzzy matching scores on sub-fields (location, winery information) are over a pre-defined threshold. If passed, data will be stored alongside the lot & lot item record. This method will ensure any record that has higher similarity on names but is not right will be filter out based on sub-fields, only the right records can pass every check. Users can later verify or correct these matches through the admin interface, ensuring a balance between automation and manual oversight.
All of this is made accessible through a dedicated admin dashboard, which allows users to browse auctions, inspect individual lots, view parsed and matched data. With features like filtering, search, and pagination across tens of thousands of entries, the dashboard plays a critical role in quality control and internal review.
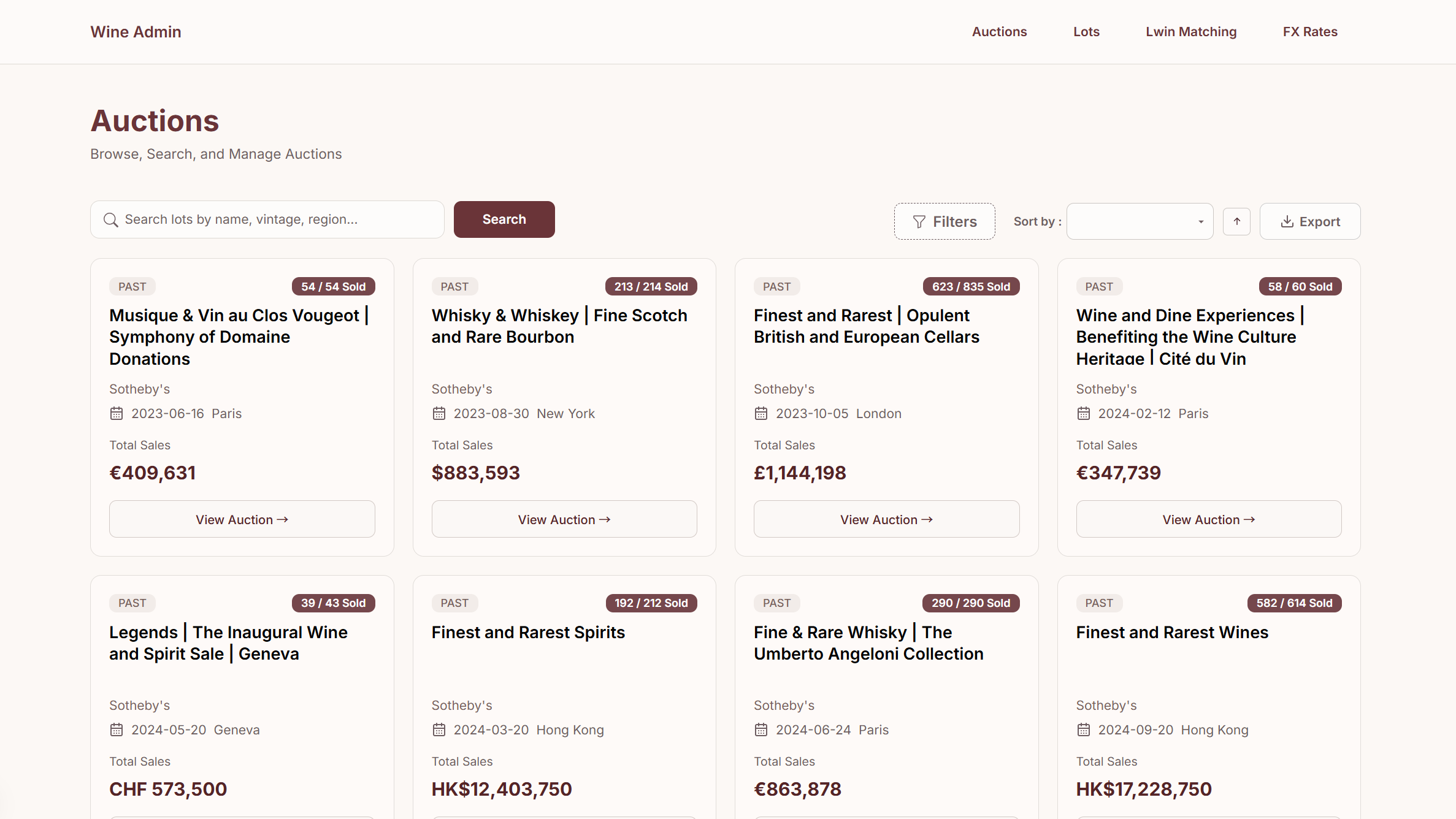
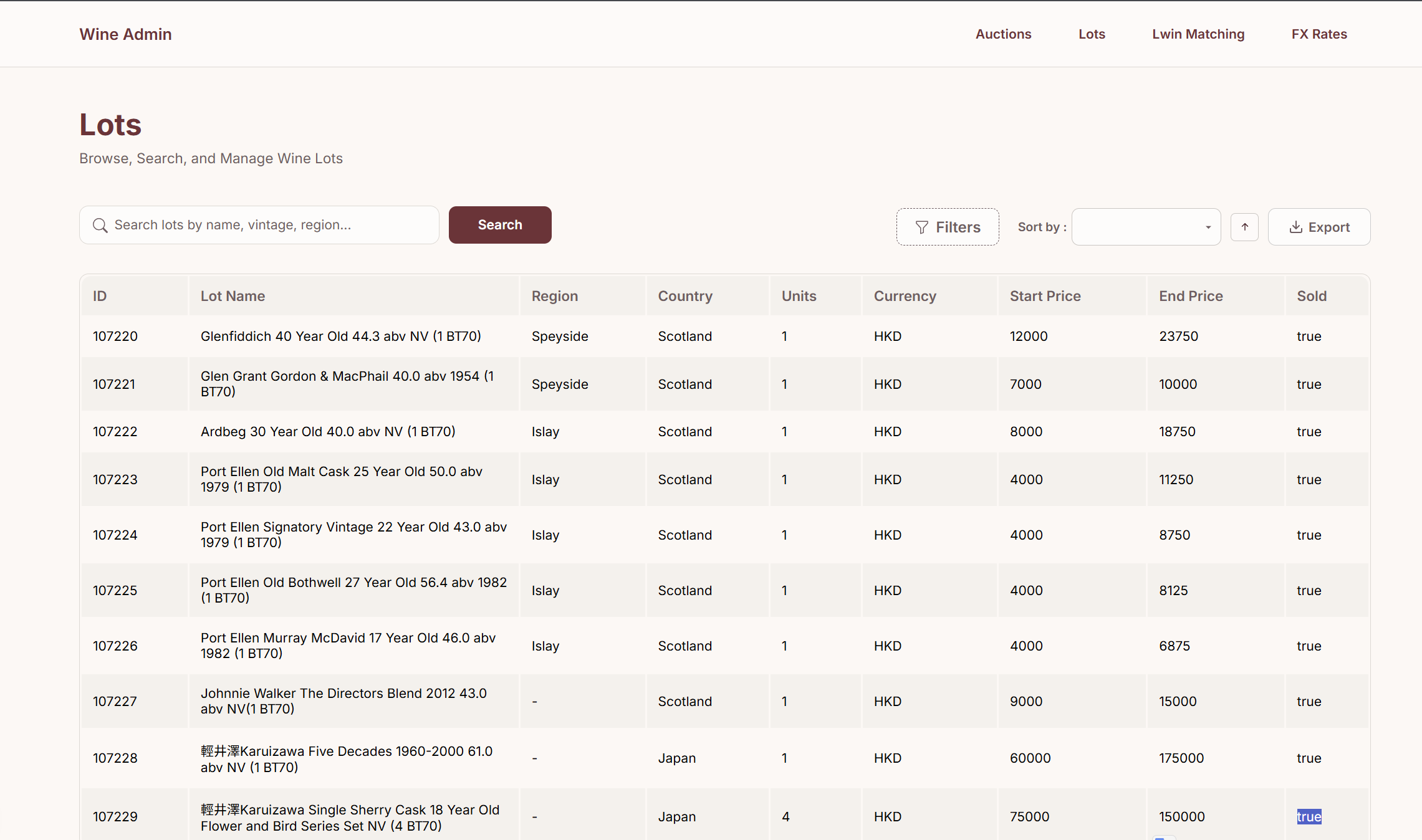
Outcomes & Impact
The initial phase has been successfully completed, aggregating nearly two million data entries from 10 auction houses. The LWIN matching engine achieved an impressive 92% accuracy, empowering analysts to conduct advanced price evaluations, competitive comparisons, and market trend analyses confidently. The robust foundation established by this platform paves the way for future innovations, including real-time auction tracking, price forecasting, and deeper market intelligence.