This blog is a supplement of deep learning topic as we already explain the fundamental knowledge in this blog: Natural Language Processing - Deep Learning I, where we will mainly focuses on CNN.
Why Deep Learning?
The reason why we apply deep learning techniques are quite obvious, which is to ues it handle thee robots’ vision. The advantage of neural network is learning and building up features to represent the input data, which help us remove the complex and limit feature selection process. However, normal neural networks couldn’t satisfy the needs. For example, if we use the classic dataset like MNIST, we would have only 784 input weights(28 x 28). However, if we scale up to choose images which has a size of 200 x 200 x 3, then we would have a total of 120,000 weights! Thus, we need more powerful neural networks.
CNN (Convolution Neural Network)
CNN is inspired by human vision because human vision is made up of many layers. There are two important mechanisms that we need to use in CNN, one of them is feature selection, and the other one is pooling.
Pooling
Pooling is a technique used for reduce spatial resolution of feature maps, and it will decrease the number of parameter and calculations. In pooling, we will separate the image into non-overlapping regions, and in each region, we collect every values and perform the set operations to the collected values.
Other than reduce spatial resolutions, another advantage that pooling has is reducing the effects of shifts and distortions brings to the output. This is because pooling saves the partial features and drop unnecessary features to keep the data more stable and average.
The image below demonstrate the most common pooling method - Max polling, where we take the max value of each region and form the new image.
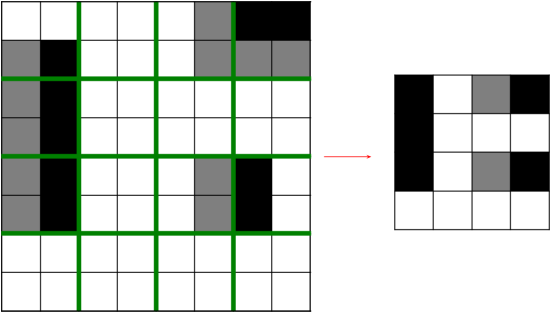
Feature Map
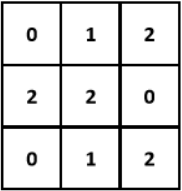
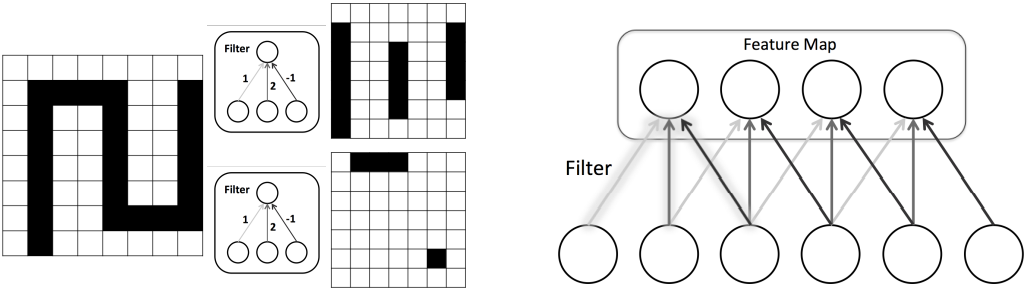
Feature maps are feature representation generated by convolution layers in CNN. Convolution is a technique used for extract features, and the operation is quite similar with pooling. In convolution, we all separate the original image into regions, but in this time we need to calculate each pixel in the region, where we multiply them by the value we have in kernel. An image of kernel is here:
And a convolution process is like the picture below:
CNN Topologies
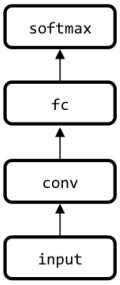
A basic CNN structure is in this sequence:
- Input → convolution → fully connected → softmax
With convolution-pooling module, the sequence become
- Input → ( convolution→pooling ) → fully connected → softmax