Unlike SQL focus on data integrity and strict transactional semantics, NoSQL focus on all applications need elastic scaling and simple operations, which operating data in isolation, some characteristics of NoSQL are: expose a simple call-level interface or protocol, offer less strict transactional guarantees, replicate and distribute data over servers… Let’s have a look at NoSQL in this blog.
Types of NoSQL
We could define NoSQL into three types: Key-Value, Document, and Wide Column.
Key-Value
Access or update a value given a key, the database doesn’t necessarily provide much functionality for the value (e.g., queries). The APIs it provides are:
- Put(key, value)
- Get(key)
- Delete(key)
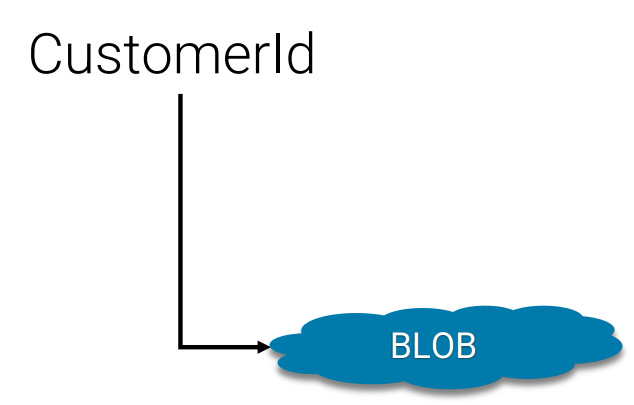
Document
Access or update a document using a key, the database will provide functionality for accessing the value (e.g., queries) The APIs it provides are:
- Put(key, document)
- Get(key)
- Find(key, filter)
- Delete(key)
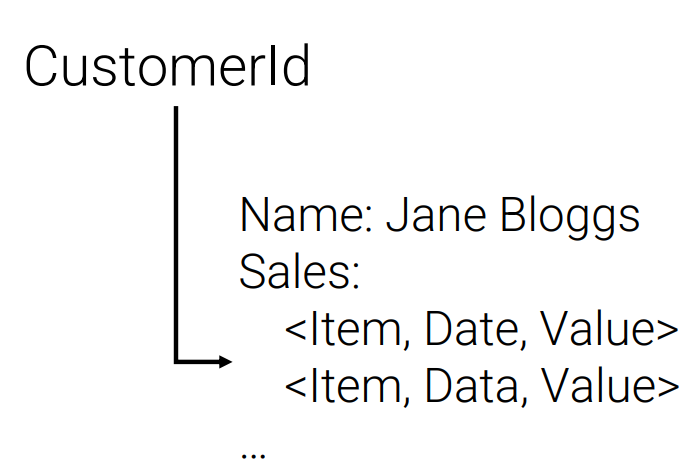
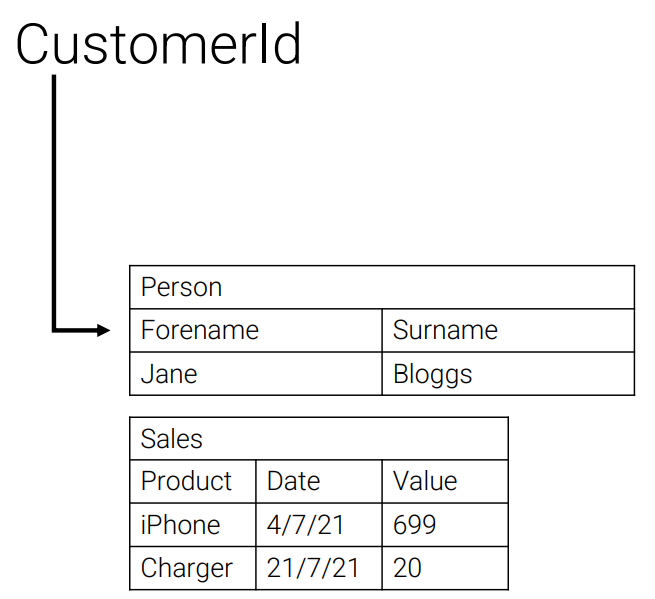
Wide Column
Access or update a collection of column families associated with a key (e.g., CustomerId links to contact details, sales details, marketing details) The APIs it provides are:
- Put(key, {column family})
- Get(key)
- Delete(key)
- Find(key, filter)
- Update(key, expression)
Data Partitioning
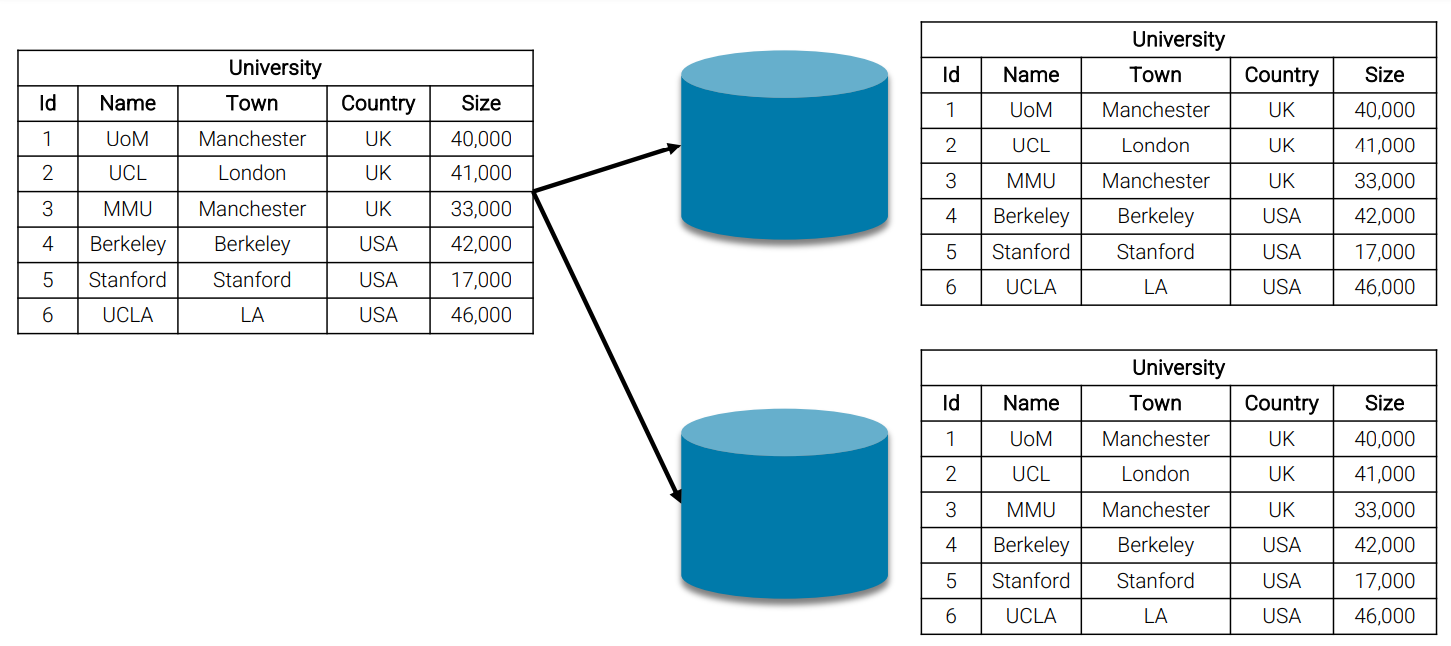
In SQL, data partitioning could be vertical or horizontal to put rows or columns together. However in NoSQL, all data associated with a key are stored in a single node, so data is horizontally partitioned, and this process has another name called sharding.
Replication
As NoSQL databases seek to scale elastically, more nodes are expected to use, and thus, node failures are also expected to exists commonly in NoSQL. In order to accommodate them, we use replication to give a high availability.
However, replication bring us some problems. In traditional transactions, people try to maintain the following ACID properties:
Atomicity: Either every action in a transaction is completed or none of them are.Consistency: A transaction does not violate constraints.Isolation: Two different transactions accessing a database can assume they are the sole user of the database.Durability: A successful transaction commit will have written the result to nonvolatile storage, such as a hard drive.
The replication is violating the consistency of data. Let’s have a look at an example of inconsistency.
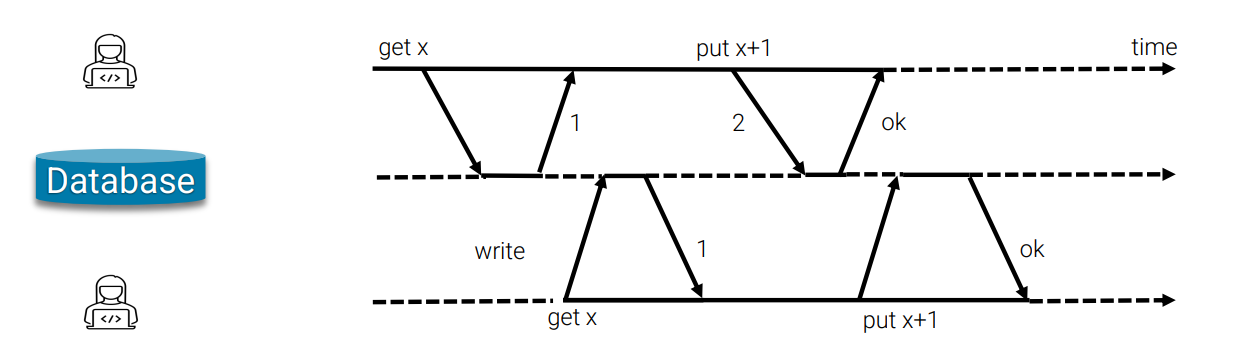
In this picture, two users are interacting with the database at the same time, where both users initiated a request to get x value from the database. However, both user initiated another request to increase x by one, and the problem is, while the user at the bottom updating the x value to 2, the database has already got the value send from the first user, which means, the database lost the update request from user at the bottom. (Should be 3 in the database but only got 2).
Two-Phase Locking
One method could be used to solve the above problem is two-phase locking (2PL). In this method we use the idea of lock to limit the interactions between users and database. There are three key rules below:
- If a transaction wants to read an object, it must first obtain a
shared lockon the object. - If a transaction wants to write an object, it must first obtain an
exclusive lockon an object. If it can’t, it must wait. - A transaction with a
read lockcan upgrade that lock to anexclusive lock(if no-one else has ashared lock)
The two-phase locking have some features:
- Transactions needs to wait to get its desired lock if the lock is assigned to other transaction.
- Transactions obtain the lock during transaction, and release the lock after commit or abort.
- Readers do not block readers and writer do not block writers, but they block each other.
- Deadlock might happen, two transactions waiting each other to release locks.
Although it has some disadvantages, we could use distributed transactions to provide ACID type guarantees. One method of distributed transaction is two-phase commit.
Two-Phase Commit
The first phase is that, all participants complete the processes of either read or write, and while finish, they are in a stage ready to commit to the database, if any of the participants didn’t ready to commit, abort the commit request. Then in phase two, we commit all the changes.
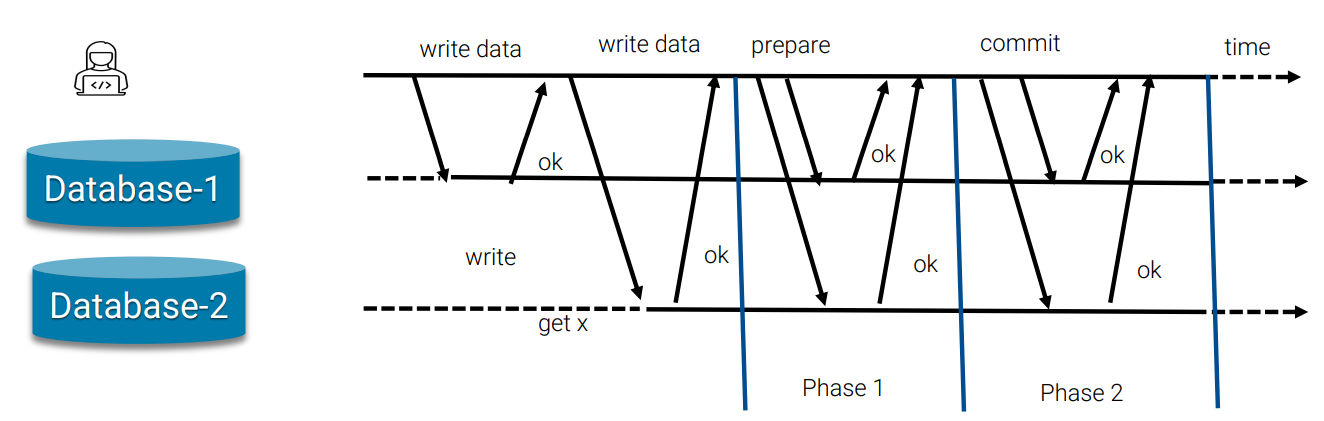
The features of two-phase commit are:
- During the preparation phase, every participant must write all the transaction’s data to nonvolatile store before responding ok.
- When a participant returns ok, it must hold locks until the coordinator asks it to commit or abort.
- When the coordinator has received an ok response to all prepare messages, it must write the decision to commit to nonvolatile store, giving rise to a commit point.
- After the commit point, the coordinator must keep trying to send commits to participants until they have all provided an ok response.
Although two-phase commit provides strong guarantees, but a failure could bring huge effects to all transactions as it might block arbitrary periods. Here are few problems might exist and their possible solutions.

Replication: Leader & Follower
The replication without update is easy, however we do need the updates applied to all replicas. The Leader & Follower structure is a common approach to support updates. Within all replicas of our database, one of them is promoted to leader and rest of them are followers, where the leader should receives update requests and forward them to followers. And followers should receive read requests from users and update requests from leader only.
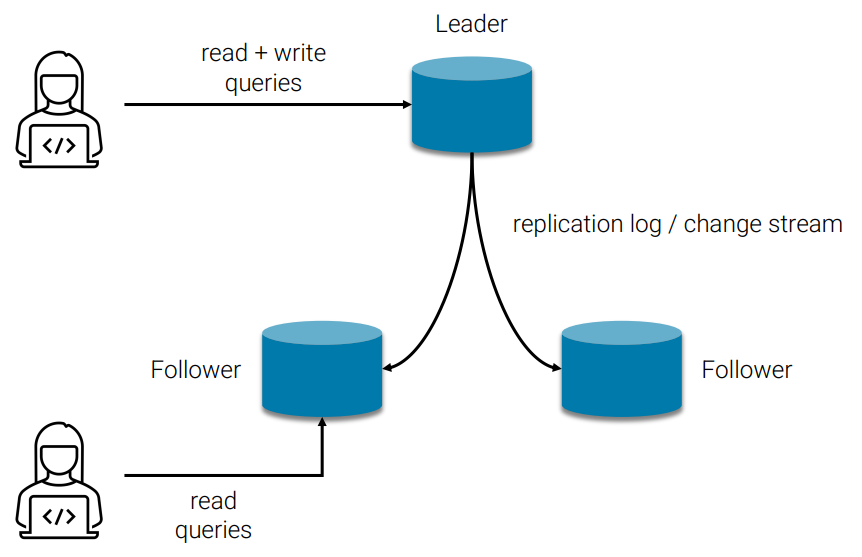
The step of adding a new follower is as below:
- Take a snapshot of leader
- Copy snapshot to the new follower
- New follower requests replication log from time of snapshot from leader
- Apply replication log
If a leader fails within the running process, we could promote another leader from all followers, and inform clients and other followers about the new leader, this process is called failover. And if a follower fails, we could still redirect the requests, and when it comes back, we should identify when it last processed a replication log from the leader, and, request and apply the replication log from that time from the leader, then it will work as normal.
Synchronous and Asynchronous Replication
We could actually split the replication into three types: synchronous replication, asynchronous replication and semi-synchronous replication.
- Synchronous replication: The leader returns when all replicas updated. This type of replication is consistent, but it blocks if any followers fail.
- Asynchronous replication: The leader returns before knowing if replicas has been updated. This method has no delay for writes being propagated, but the cons are obvious, it might leeds to inconsistency if leader fails
- Semi-Synchronous replication: The leader returns when it knows one replica updated. It will not lost data if there’s a single node failure, but we need more complicated protocol if nominated follower is down.
Replication logs
There are few types of replication logs:
- Statement-based: send the (e.g. SQL) query or operation from the leader to the followers.
- Write-ahead log based: send the physical representation of the modified disk blocks, as used for recovery.
- Logical log based: send the changes at the level of the data model, e.g., add, delete, modify tuple
Combining Replication and Partitioning
When we are handling data in a shopping cart, we need both scalability and availability which could be satisfied by partitioning and replication, where we first partition data by key, and then replicating the partitions. In Dynamo NoSQL database:
- Each write is sent to several replicas, and succeeds when a threshold number succeed.
- Each read is obtained from several replicas, and the client determines what value should be used (e.g., by application logic or a heuristic such as most recent).