Batch processing - a word describing tasks that can run without user interactions, or can be scheduled to run as resources permit. Batch data sets might be huge and need parallel processing. MapReduce is a programming model designed for batch processing, including two steps: ‘map’ and ‘reduce’.
MapReduce - ‘Map’ and ‘Reduce’
Some concepts
Jobis the unit of work to be performed, it could consist of severalmapandreducetasks.Splitis a part of the input.Taskare map or reduce functions created and run for each split or partition.Task trackertracks the progress of each of the map or reduce tasks on a node and keeps the job tracker informed of progress.Job trackercoordinates the different tasks comprising a job.
Map
A map function is to generate a key-value pair (key 2, value 2), given a key ‘key 1’ and a value ‘value 1’.
map(key1, value1) -> [(key2,value2)]
## Pseudo-code
map(documentId key1, document value1) {
for each word w in value1 do
emit(word w, 1)
}
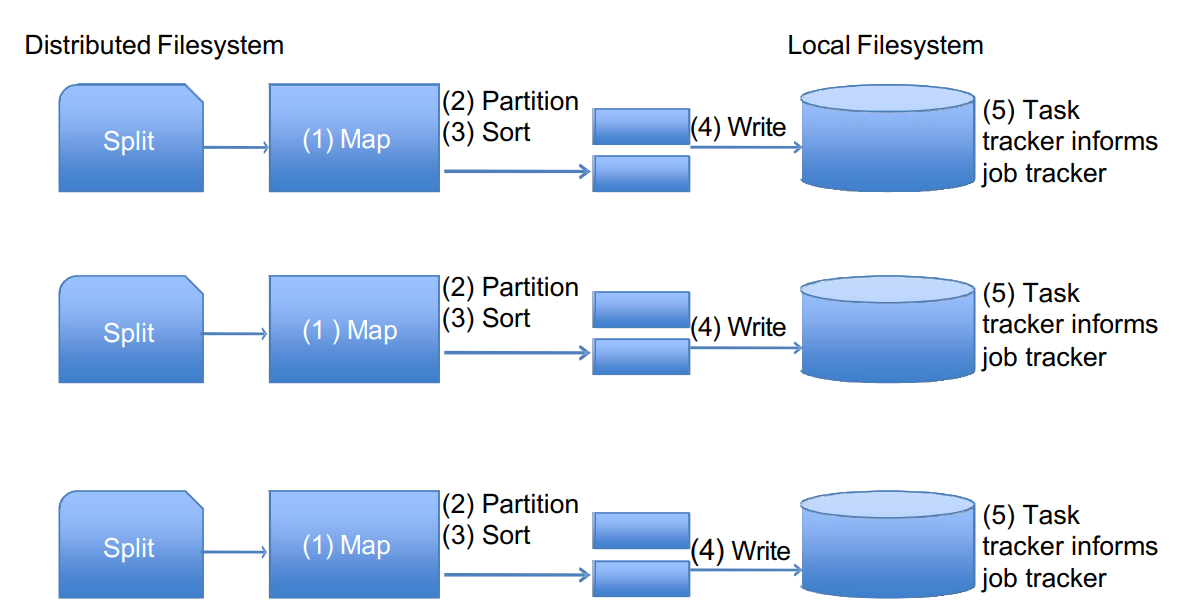
A map task is created for each split, and if possible, the map function will be run on the node where the input data is stored. Here are steps to take for a map task:
- The map task runs on the split, generating key-value pairs.
- The output of the map is partitioned into groups, for sending to reduce tasks, typically by hashing.
- The partitions are sorted by key.
- Output is written (to the local filesystem).
- The job tracker is informed by the task tracker when a task has completed.
Reduce
A reduce function is to return a new collection of key-value pairs, given a ‘key 2’ output by ‘map’, and a collection of all values ‘value 2’ with that key.
reduce(key2, [value2]) -> [(key3, value3)]
## Pseudo-code
reduce(word key2, list of count value2) {
sum = 0
for each count in value2 do
sum = sum + count;
emit(word key2, sum)
}
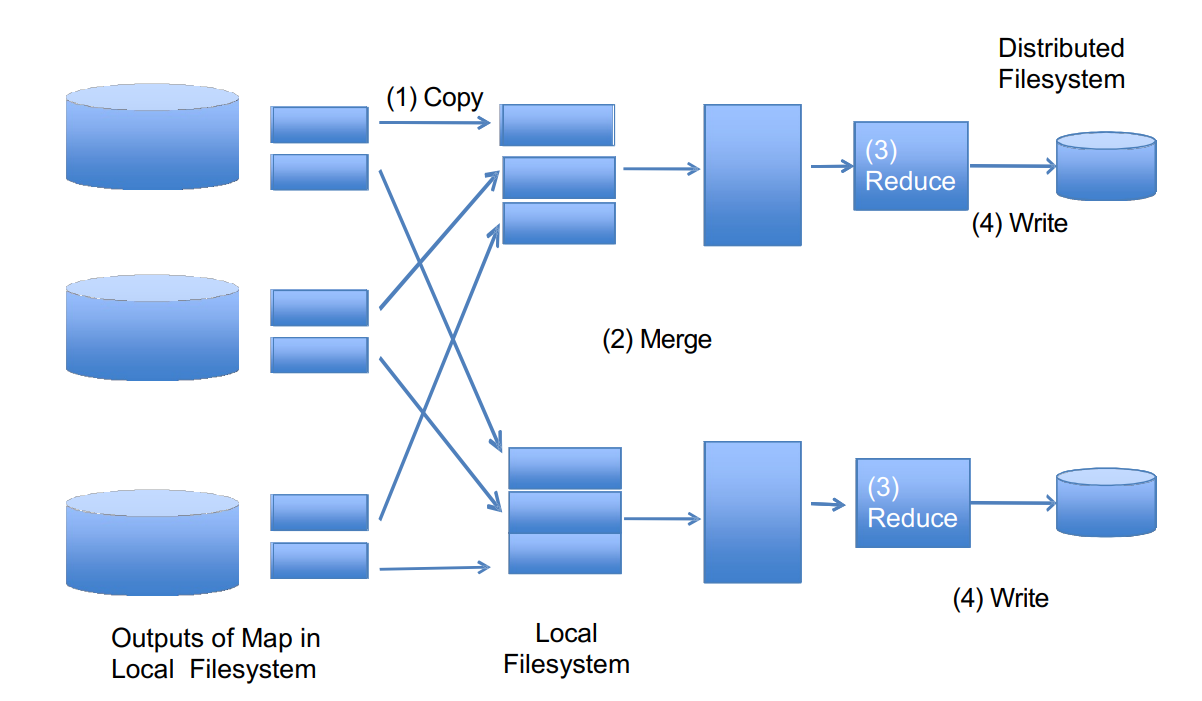
Here are steps for a reduce task:
- Relevant map partitions are copied to the associated reduce nodes.
- Data from different maps is merged to produce the inputs for individual reduce operations.
- The reduce task is run.
- Outputs are written to the distributed filesystem.
An Example
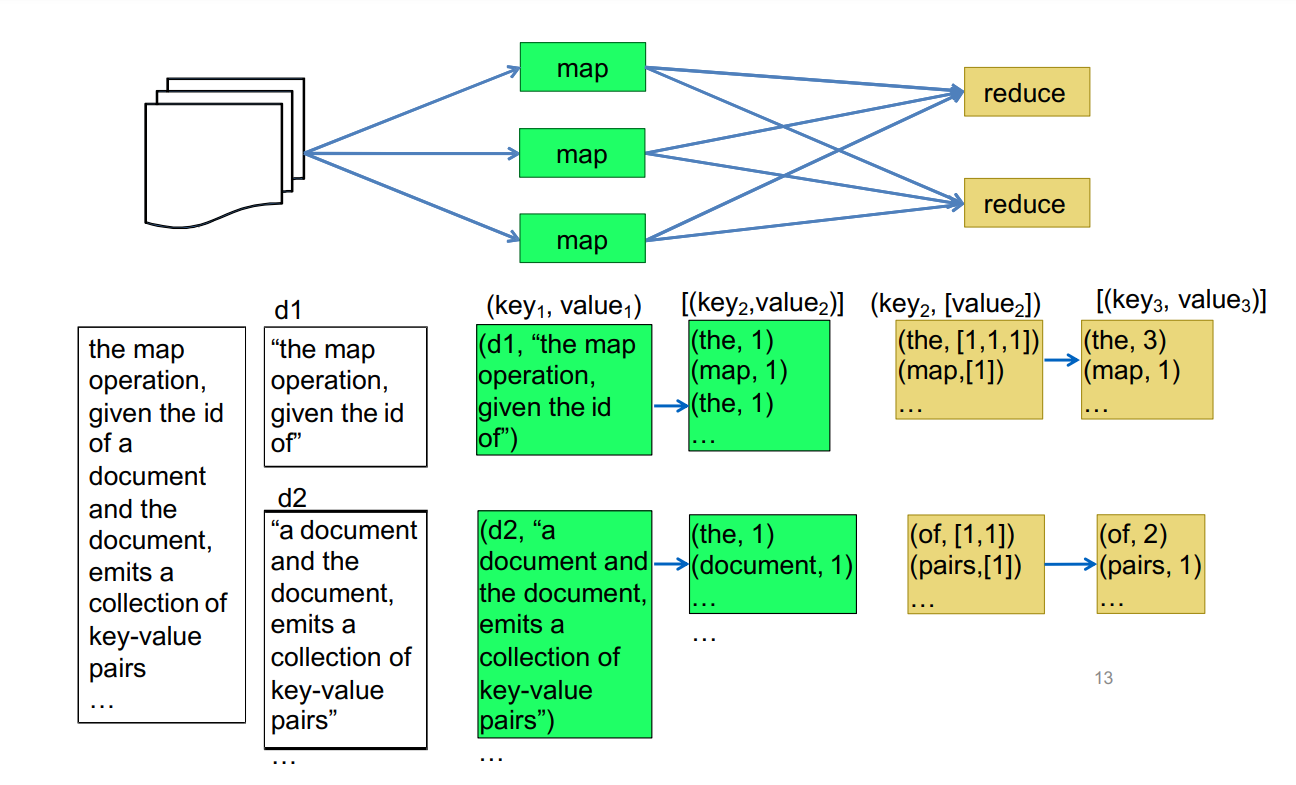 The above picture demonstrate a word-count program contains
The above picture demonstrate a word-count program contains map and reduce operations, where we can see that the map operation split the document into list of words and record its appearance, and reduce combine all same words and accumulate their occurrences.
Basket Analysis
Basket analysis is another web-scale, data intensive application about users shopping on the internet. It records the value of each basket of products from customer’s purchases. A simple analysis could be average the total prices of a customer’s all purchases records.
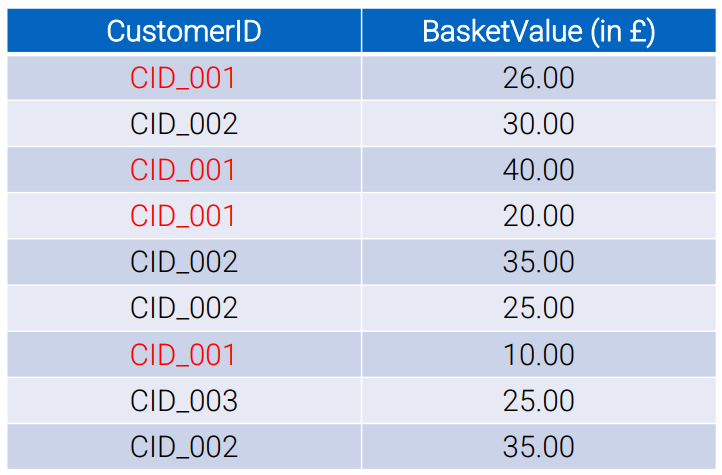
The graph above is a record of customers and their interactions, we will now write the pseudo-code for both map and reduce operations.
## Map
map(key, value) {
for each (customerID CID, basketValue v) in value do
emit(customerID CID, basketValue v)
}
## Reduce
reduce(customerID key, list of basketValue value) {
sum = 0
count = length(value)
for each v in value do
sum = sum + v;
emit(customerID key, sum/count)
}
MapReduce Design Pattern
There are some patterns while we are using MapReduce for better solving some common tasks, here we will introduce Summarization Patterns(Numerical Summarization), Inverted Index Pattern, Filtering Pattern and Join Pattern.
Summarization Patterns
In this pattern, we want to send less data from mappers to reducers while providing what the reducer needs. An example is numerical summarization.
Where we interest in giving data like [(“the”, 2), (“two”, 2)] instead of [(“the”, 1), (“a”, 1), (“the”, 1), (“a”, 1)]. Some aggregates could be used
are min, max or sum. Below is the pseudo-code for map and reduce.
map(documentId key1, document value1){
localCache = Hashmap(String -> Integer)
for each word w in value1 do
if (localCache.containsKey(word))
count = localCache.get(word);
localCache.put(word,(count + 1));
else
localCache.put(word,1)
endif
endfor
for each (word,count) in localCache do
emit(word w, count)
end-for
}
reduce(customerID key, list of basketValue value) {
running_count = 0
running_sum = 0
for each (count, sum) in value do {
running_count = running_count + count;
summing_sum = running_sum + sum;
}
emit(customerID key, (running_sum/running_count))
}
Inverted Index Pattern
• An inverted index pattern invert the relationship between document and contents. Generally, the data is represented as:
Name: d1
Contents: hello there world
But in inverted index pattern, we want it to be:
hello → d1
there → d1
world → d1
The pseudo-code for map function in this pattern is:
Map(key, value):
fetch identifier of input d
for each v in tokenise(value)
emit(v, d)
Filtering Pattern
As the name describes, the filtering pattern will filtering some data from the data set. Some rules of filtering could be producing representative examples,
choosing the best k examples or removing duplicated data.
Pseudo-code:
Map(key, value):
for each v in value
if (inDictionary(v))
emit(v, 1)
Join Pattern
MapReduce can partition the data from the tables to be joined on their join columns, we need two mappers to read from different inputs, then the infrastructure does most of the join. Pseudo-code:
MapA(key, A):
for each row in A
emit(A.u, “A” + row)
MapB(key, B):
for each row in B
emit(B.v, “B” + row)
Reduce(key, List of rows R):
for each a in R with prefix “A”
for each b in R with prefix “B”
emit(a, b)