In this article, we are going to look at general steps of text pre-processing.
Tokenization
Word-Based Tokenization
Tokenization is the first step of text pre-processing, it is to split a bunch of text into a list of tokens. As an example, we could split “a cat on a pat” to [“a”, “cat”, “on”, “a”, “pet”]. For the most basic Tokenization method, we do white space-delimited sequence, like the above example. However, not all languages use white space, like Chinese (我喜欢西兰花), and we also have to consider punctuation signs, if we want to split “white space-delimited sequence”, we don’t want the result to be [“white”, “space-delimited”, “sequence”], which breaks the origin meaning of the words.
There are few others conditions we have to consider:
- White Space
San Francisco & in spate of, these words should be in one token because only two or three words together could perform the correct meaning. - Abbreviated forms
what’re, I’m is what + are, I + am
King’s coming is King + is + coming - Possessives
King’s speech, this is completed different with King’s coming, because'shas completely different meaning in two combinations
In order to consider all above situations, tokenization is performed with the following steps:
- Initial segmentation (mostly on white-space)
- Handling abbreviations and apostrophes
- Handling hyphenations
- Dealing with (other) special expressions
– emails, URLs, emoticons, numbers, …
Note that there are no firm rules for tokenization, it has to be consistent with the rest of an NLP system. Moreover, it is necessary to avoid over-segmentation.
Byte-Pair Encoding
To decrease the influence of OOV words, we have another method of tokenization - Byte-Pair Encoding. It consist of two parts, token learner & token segmenter.
Token Learner
In token learner, split the words into individual characters to form a vocabulary $$\{A, B, C, D, a, b, c, d, …\}$$
and repeat the following steps:
- Choose any two symbols that are most frequently adjacent
- Merge them together and add to the vocabulary
- Replace every adjacent characters merged previously into the merged form in the corpus
Token Segmenter
After we get the merged vocabulary, on the new data, perform same merges, and then we could get the tokenization down by now.
This method could greatly reduce the number of unseen tokens.
Normalization
Normalization is the second step, we map tokens into normalized forms like below:
- {walks, walked, walk, walking} → walk
- {B.B.C., BBC} → BBC
- {multi-national, multinational} → multinational
- {Duesseldorf, Düsseldorf, Dusseldorf} → Dusseldorf
We have two main approaches for normalization: Lemmatisation & Stemming.
Lemmatisation
The key idea of lemmatisation is the reduction to dictionary headword, here are few examples:
- {am, are, is} → be
- {horse, horses, horse’s, horses’} → horse
- {life, lives} → life
We have to eliminate all tense or plural form or any other forms which cause a transform to the original words. To do this, we could have two methods:
- Dictionary look-up
The problem of this method is that, the efficiency might be slow because every word need a look-up in dictionary, and we couldn’t takeOOV(Out of Vocabulary) words into account. - Morphological Analysis
Morphemesare sub-words which includesstemandaffixes(prefix & suffix)
We can do morphological analysis after we identity what is a stem and what are affixes in a word. However, this method has some disadvantages that can’t be ignored. First, for some verbs we might still need a dictionary because they have some special inflections, such as “build” will be inflected into “built”. And second, derivational morphology (The formation of a word from stem and affixes) is a messy, consider the picture below:
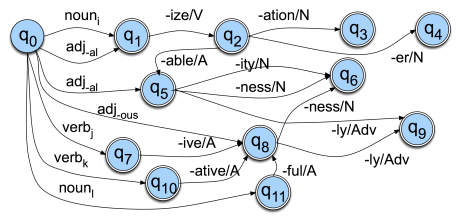
The change of states is computationally expensive.
Stemming
Stemming is much more straight forward compare to Morphological Analysis Lemmatisation, as it “chops” the end of words immediately.
- changing → chang
- changed → chang
- change → chang
As you can see from the example above, we will inevitably encounter
over-stemming(sometimesunder-stemming) and generate forms that are ’not words'.
Nowadays, we have many stemmers developed, one of them is called Porter Stemmer, which meanly focus on suffix stripping, here are its rough processing steps:
- Get rid of plurals and -ed or -ing suffixes
- Turn terminal y to i when there is another vowel in the stem
- Map double suffixes to single ones
- Deal with suffixes, -full, -ness etc.
- Take off -ant, -ence, etc.
- Tidy up (remove –e and double letters)