In a shared nothing infrastructure, data storage, update, access and processing takes place across a collection of networked machines. To enhance the performance, processing needs to be take place in parallel, which we have to distribute data, and that’s partition. This article will gives an rough idea of partition techniques and details needs to be consider.
Partition
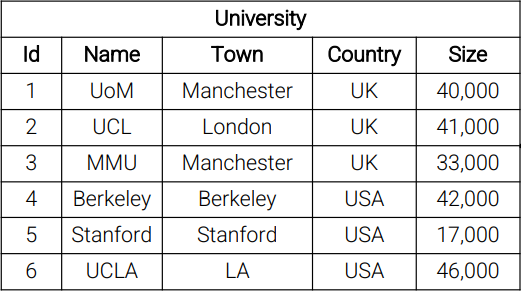 By definition, partition involves deciding how to assign data from a sources to distributed nodes.Take the above image as an example, we could do partition in these ways:
By definition, partition involves deciding how to assign data from a sources to distributed nodes.Take the above image as an example, we could do partition in these ways:
-
Random or Round Robin:
Data is assigned as it is inserted across different nodes.Pros Cons Uniform initial distribution Querying involves accessing all notes Easy to rebalance on update -
Range based Partition:
Partitioning often assumes some form of key-value data model. Then partitioning relates to the key Key range: each partition is associated with a range of values for the key (e.g. alphabetical or numerical).Pros Cons Focused range queries on key Risk of hot spots for popular keys Focused direct access on key Uniform distribution not intrinsic Rebalancing can be expensive Only helps for key-based requests -
Hash based Partition:
Partition based on the hash of the keys.
Assume we have Hash(String) -> Integer, if there is n parition, partition(key) = return(Hash(key) mod n)Pros Cons Uniform distribution with certain keys Risk of hot spots for popular keys Focused direct access on key No support for range queries Rebalancing can be expensive Only helps for the requests that have the key -
Meaning based Partition:
Partitioning by key means choosing a suitable keyDesirable Examples Useful for range access requests Size Useful for direct access requests Name, Town Diverse values Id, Name, Town, Size Not subject to skew Id, Name, Town, Size
Repartitioning
Skew and Hot Spots
Skew is when partitioning is uneven. For example, a partitioning on the first letter of Country in the University table.
A hot spot arises when the load is unevenly balanced. For example, many more people may look up some
universities than others.
Method
Repartitioning involves moving the data from one partition to another.
Example: Partition by Id, use a hash function Hash(x) = Id(x) mod #nodes
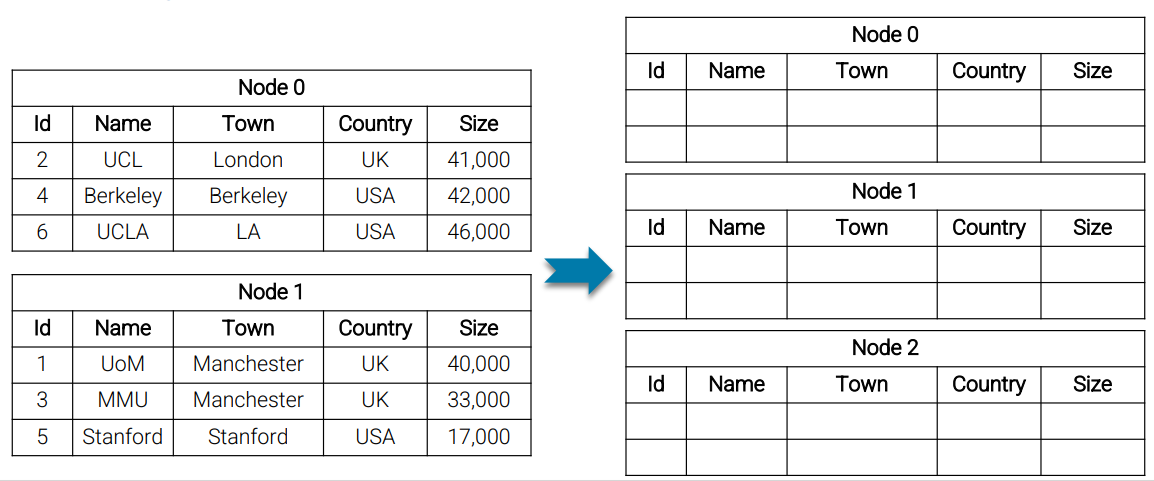 How many tuples need to change node?
How many tuples need to change node?
In this case of uniform distribution and mode-based partitioning, the number of data need to be repartitioning is:
To-Distribute = 1 - 1 / #final-nodes
In this example, the number of data need to be distribute is:
1 - 1/3 = 0.666, which is 0.666 * 6 = 4
In order to reduce the cost of repartitioning, it is possible to have more partitions than nodes. Then repartitioning for a new node involves moving selected partitions to the new node.
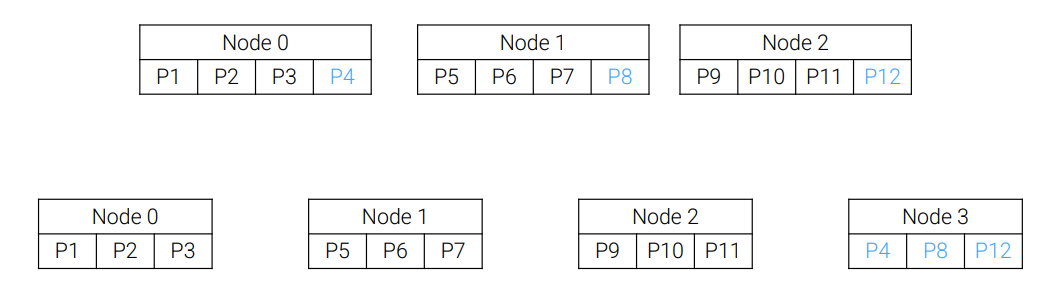
Two steps need to be taken to find a partition for value v:
- Hash v to a partition number
- Use a lookup table to identify the node of this partition
In this case the fraction of data need to be moved is: 1 / #nodes + 1
In the previous example the fraction is 1/4
Secondary Indexes
The Ranging and Hashing methods are better performed when key is widely used. NoSQL are always designed to support applications use Id or names as primary key. However, it’s better for us to have multiple access routes to avoid scanning. In this case we use secondary index - the index on an attribute that has not been used for partitioning.
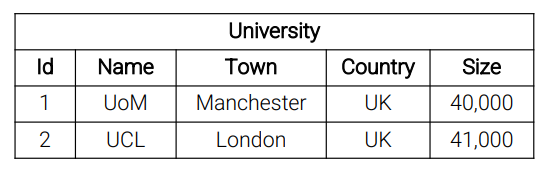
Example: In this table, the data is partitioned by name. Does the hash index on the partition helps?
| Query | Does partition index help? | Useful Additional Index |
|---|---|---|
| How many students attend UCL? | Yes | N/A |
| Which Uni have > 40,000 students | No | Range index on size |
| Which Uni are in Manchester | No | Hash or range index on town |
Local Secondary Index
A key question is that where should we store these secondary index? Here are few options to do it:
-
Store the secondary index on the same node as the data it is indexing.
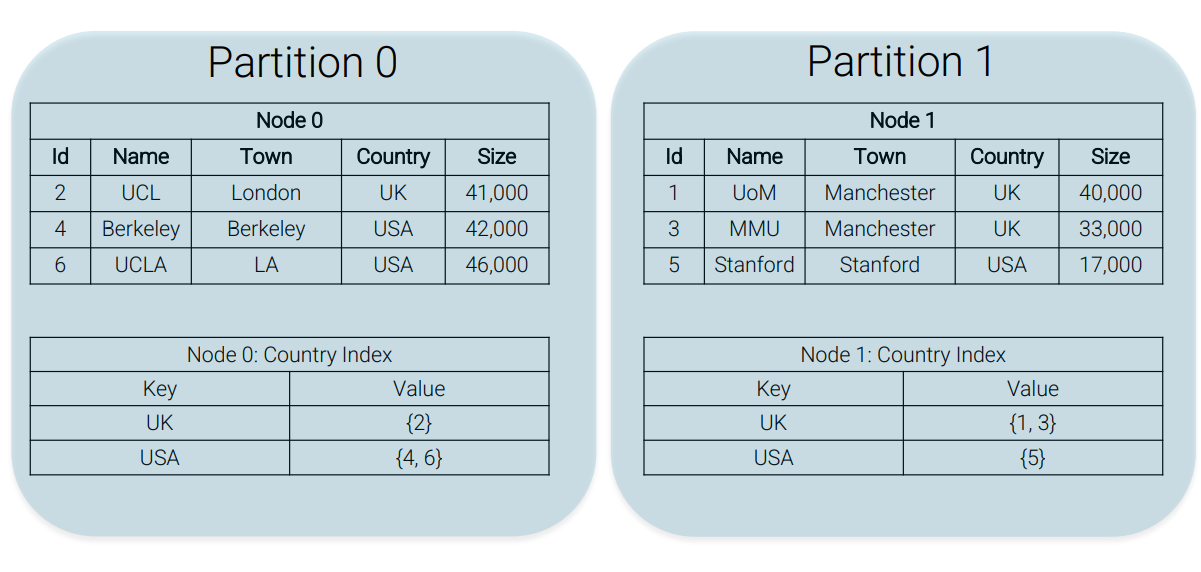
Pros Cons Updating a document leads to local index changes (so no distributed transactions) A lookup needs to go to every transaction, leading to many index lookups -
Store the secondary index partitioned by term: a single distributed index.
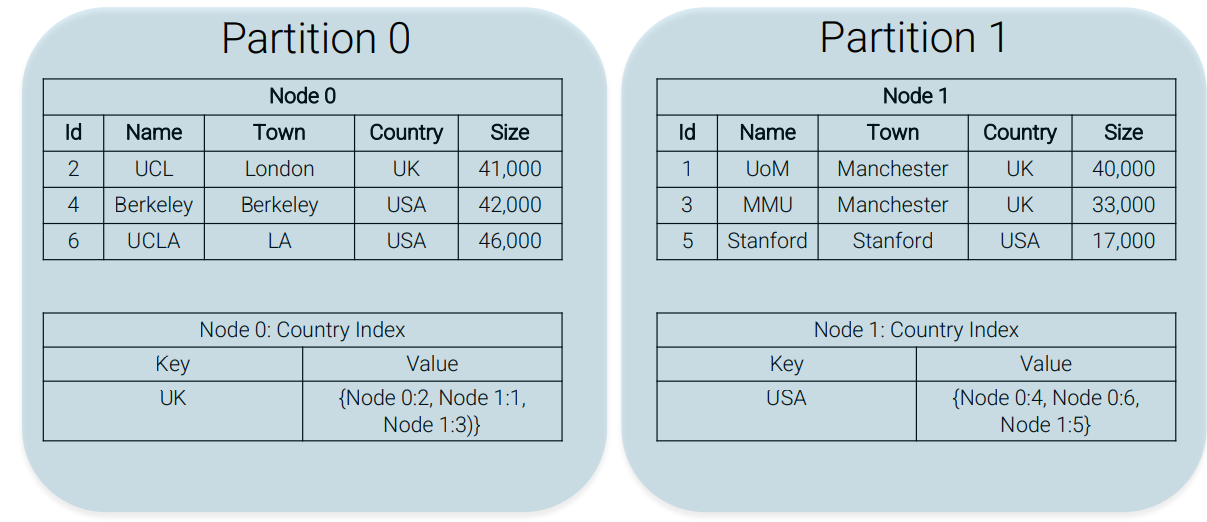
Pros Cons Index lookups no longer need to go to all nodes (note some index lookups will have no hits) Updates to a document on a node now also lead to index updates (and thus potentially to distributed transactions)
Partitioning for Evaluation
After we talked about how to do partitioning, we should discuss about when data need partitioning. As an example, Uni-Sizes is hash partitioned on ‘Name’, Uni-Places is hash partitioned on ‘Town’, and we want these two partition to join on ‘Name’.
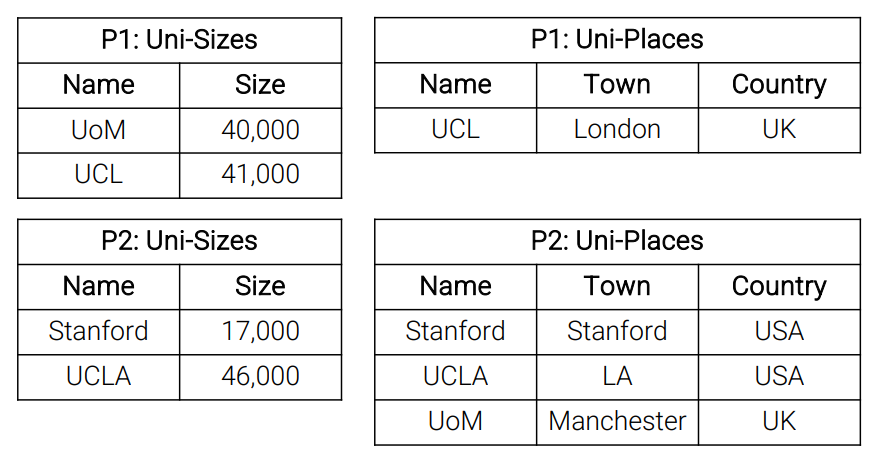
We need to repartition Uni-Places as it is not partition on ‘Name’, and the steps are:
- Partition Uni-Places on Name to give P1’, P2’.
- Join(P1:Uni-Sizes, P1’: Uni-Places) on Node 1
- Join(P2:Uni-Sizes, P2’: Uni-Places) on Node 2